
 VI
VI EN
EN JP
JPSun* Bear giành chiến thắng tại cuộc thi online về xử lý ngôn ngữ tự nhiên quy mô toàn quốc
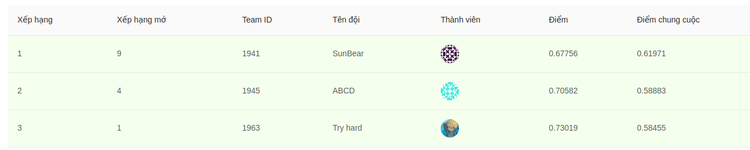
Với điểm số cao nhất 0,61971, Sun* Bear - sản phẩm được tạo ra bởi AI Team đã giành chiến thắng ở hạng mục Hate Speech Detection on Social Networks - cuộc thi online do ban tổ chức Hội nghị thường niên lần thứ 6 về Xử lý ngôn ngữ tự nhiên và tiếng nói cho tiếng Việt tổ chức (VLSP 2019).
Trong lần thứ 6 tổ chức, Ban tổ chức chương trình VLSP 2019 đã tổ chức một cuộc thi gồm 4 hạng mục để nhằm tháo gỡ một số bài toán hóc búa trong xử lý ngôn ngữ tự nhiên tiếng Việt là Hate Speech Detection on Social Networks (Nhận diện các nội dụng tiêu cực, độc hại trên mạng xã hội), Vietnamese dependency parsing (Xử lý ngôn ngữ tự nhiên tiếng Việt); Automatic Speech Recognition (Nhận dạng tiếng nói); Text To Speech (chuyển đổi từ văn bản thành giọng nói).
Chương trình thu hút các nhóm nghiên cứu trong nước chia sẻ kinh nghiệm, thúc đẩy hợp tác giữa các trường đại học, viện nghiên cứu và doanh nghiệp công nghệ.
Tham gia VLSP 2019, Sun* tham gia ở 2 hạng mục là Hate Speech Detection on Social Networks và Text To Speech.

Trong hạng mục Hate Speech Detection on Social Networks, ban tổ chức gửi cho các đội thi 20.000 bài post hoặc comment từ Facebook đã được dán nhãn (bài viết bình thường/bài post có nội dung nói tục, chửi thề, không đúng thuần phong mỹ tục/bài có nội dung xấu, độc hại hướng đến đối tượng cụ thể) để training cho hệ thống của mình.
Khi giai đoạn này hoàn thành, ban tổ chức tiếp tục gửi đến các đội thi 5.000 bài post hoặc comment chưa được dán nhãn để hệ thống do các đội đã phát triển thực hiện thao tác phân loại và gửi bài thi về cho ban tổ chức.
Kết quả chung cuộc, Sun* Bear của AI Team đã xuất sắc giành chiến thắng với điểm số vượt trội (0,61971) so với 2 đối thủ xếp ngay phía dưới. Đó là sản phẩm ABCD đến từ Trường Đại học Công nghệ Thông tin , Đại học Quốc gia Thành phố Hồ Chí Minh và Try Hard của Vietnam AI System, với điểm số lần lượt là 0,58883 và 0,58445.
Ngoài ra, trong cuộc thi này, AI Team cũng tham gia ở hạng mục Text To Speech. Theo đó, ban tổ chức gửi cho các đội thi 1000 đoạn audio có thời gian 45 phút với giọng miền Bắc và 15.000 đoạn audio có tổng thời gian 23 giờ với giọng miền Nam.
Sau đó, ban tổ chức gửi cho các đội thi 120 câu và yêu cầu, đội thí sinh ra sản phẩm có thể đọc được 120 câu này theo 2 giọng đọc dựa trên dữ liệu training đã cho trước đó. Sau đó, ban tổ chức sẽ trộn lẫn các file ghi âm thật và file giọng đọc tổng hợp rồi gửi ngẫu nhiên cho 24 người. Những người này sẽ các nghe file audio, phân biệt đâu là người đọc, đâu là máy đọc rồi chấm điểm dựa trên chất lượng của các file.
Kết quả của hạng mục này sẽ được ban tổ chức công bố trong Hội nghị chính thức về Xử lý ngôn ngữ tự nhiên và tiếng nói cho tiếng Việt, diễn ra ngày 13/10/2019 tại ĐH Khoa học tự nhiên, 19 Lê Thánh Tông, Hoàn Kiếm, Hà Nội.
Hãy cập nhật những thông tin mới và hấp dẫn nhất từ Sun* News vào 8h00 và 13h00 hàng ngày!




 LOGIN WITH G-SUITE ACCOUNT
LOGIN WITH G-SUITE ACCOUNT